Kafka面试题,2024-11-16-Kafka-3
本文给大家分享的是Kafka面试题,2024-11-16-Kafka-3的相关内容!
在面对Kafka面试时,你是否有过困惑?如何理解Kafka的工作原理?如何处理高并发的数据流?如何优化Kafka的性能?
这些问题可能在你的面试中出现。2024年11月16日,我们将一起探讨Kafka-3,深入理解这个分布式流处理平台的核心概念和实践技巧。
一、Kafka面试题
Kafka面试题深度解析
在大数据与流处理的领域里,Apache Kafka无疑是一个耀眼的明星。掌握Kafka的相关知识是必不可少的。
下面,我们就来探讨几个Kafka面试中常见的问题,以帮助你更好地准备面试。
1.什么是Kafka?
Kafka是一个开源的流处理平台,由Apache软件基金会开发。它主要用于构建实时数据流管道和应用,能够在分布式环境中处理大量数据,并具备高度的可扩展性和容错性。
2. Kafka的主要应用场景是什么?
Kafka广泛应用于日志收集、消息系统、用户活动跟踪、实时分析等多个场景。它的高性能和可靠性使得它成为处理大数据流的理想选择。
3. Kafka的基本架构是怎样的?
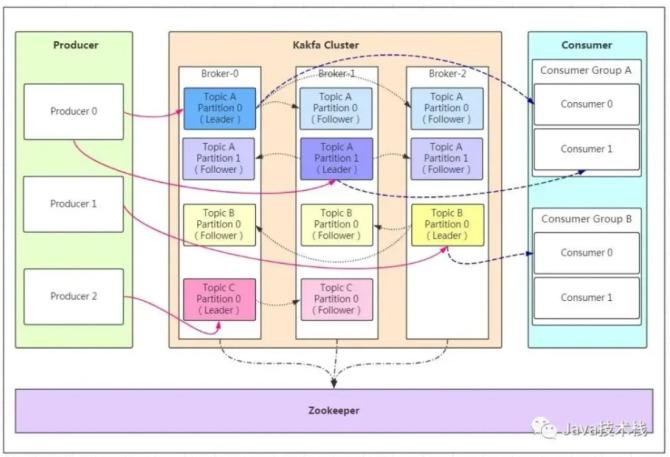
Kafka的基本架构包括Producer(生产者)、Broker(服务器)、Consumer(消费者)和Topic(主题)。生产者负责发送消息到指定的主题,消费者从主题中读取消息进行处理。Broker负责存储和管理这些消息。
4. Kafka的消息是如何存储的?
Kafka采用分区的方式存储消息,每个主题可以分成多个分区,每个分区在物理上对应一个文件夹,文件夹中存储了该分区的所有消息文件和索引文件。
5. Kafka如何保证消息的可靠性?
Kafka通过数据持久化、备份和容错机制来保证消息的可靠性。它采用分区副本的策略,每个分区都有多个副本,当某个Broker宕机时,其他Broker会接管其副本,确保消息不丢失。
6.如何处理Kafka中的消息丢失和重复问题?
Kafka通过消息的唯一ID和事务性API来处理消息丢失和重复问题。生产者可以在发送消息时指定一个唯一的消息ID,消费者在处理消息时可以检查这个ID,确保不处理重复的消息。
Kafka还支持事务性API,可以在一系列操作中保证消息的原子性和一致性。
7. Kafka的性能如何优化?
Kafka的性能优化可以从多个方面入手,例如调整Broker的配置参数、优化Producer和Consumer的参数设置、合理规划Topic的分区数量等。
还可以结合Kafka的监控工具进行性能分析和调优。
通过深入了解这些问题和答案,相信你在Kafka面试中会更加从容不迫,展现出自己的专业素养和深厚实力。
二、2020-11-16-Kafka-3
[2020-11-16-Kafka-3]是一项重要的数据处理技术,被广泛应用于大数据系统和实时数据流处理中。它是由Apache软件基金会开发的分布式流处理平台,旨在解决实时数据流处理的各种挑战。该技术采用高效的消息传递机制,能够处理大规模数据流,并实现高吞吐量和低延迟的数据处理。
[2020-11-16-Kafka-3]的核心架构包括若干个基本组件,如生产者、消费者、主题和分区等。生产者负责将数据发布到Kafka集群,而消费者则从Kafka集群中读取数据进行处理。主题用于将数据分类存储,而分区则用于实现数据的水平扩展和负载均衡。
[2020-11-16-Kafka-3]提供了高度可扩展性和容错性,能够处理数以千计的消息,并且能够容忍集群中的节点故障。这使得它成为大规模数据处理的理想选择,尤其适用于需要高吞吐量和低延迟的实时数据处理场景。
[2020-11-16-Kafka-3]还提供了丰富的API和工具,支持多种编程语言和数据处理框架。
除了基本的消息传递功能外,它还可以与流处理器、数据存储系统和监控工具等集成,为用户提供全面的数据处理解决方案。
[2020-11-16-Kafka-3]是一项强大的数据处理技术,具有高度可靠性、可扩展性和灵活性,适用于各种数据处理场景,并且在大数据系统和实时数据流处理中发挥着重要作用。
本篇内容主要介绍kafka面试,如想了解更新相关内容,关注本站,每天分享实用生活技巧和各种职业技能经验。
相关文章
猜你喜欢
-

阿里面试必备:100个高频Spring面试题助你一臂之力(面试必问之spring面试题)
本文给大家分享的是阿里面试必备:100个高频Spring面试题助你一臂之力(面试必问之spring面试题)的相关内容! 你是否对即将参加的阿里面试感到紧张? 是否...
-
已拿32k小米Android高级开发offer
本文给大家分享的是已拿32k小米Android高级开发offer的相关内容! 你是否曾梦想过在科技的前沿,用代码书写未来?是否期待过在一家全球知名的科技公司,实现...
-
面试题:请你说一说Spring中IOC和DI的含义应该怎么回答
本文主要提供面试题:请你说一说Spring中IOC和DI的含义应该怎么回答相关内容介绍。 在探索Spring框架的奥秘时,我们不可避免地会遇到两个重要概念:IOC...
-
Java开发面试题(java面试题很急)
本文给大家分享的是Java开发面试题(java面试题很急)的相关内容! 你是否对Java开发面试感到困惑?是否在寻找一些实用的面试题来提升你的技能?这篇文章将为你...
-
C语言6个有趣的面试题(C语言面试题)
本文给大家分享的是C语言6个有趣的面试题(C语言面试题)的相关内容! C语言,被誉为编程的基石,它的简洁、高效和灵活一直吸引着无数的程序员。 但是,你是否知道在面...